🧪 Reproducible Deep Learning Experiments with One Command: GPU-Jupyter

🚨 The Reproducibility Crisis in ML & DL
In science, reproducibility is a cornerstone of credibility. But in the fast-evolving field of machine learning (ML) and deep learning (DL), reproducing research has become unexpectedly difficult. A recent meta-study showed that only about 6% of papers at leading AI conferences shared their code, and only a third shared their data. Reproducibility is further hampered by vague setup instructions, missing package versions, and evolving GPU dependencies.
This setup barrier is particularly severe in ML/DL, where:
- A high number of libraries (stacks) are required
- Hardware access (e.g., GPUs) is essential, and
- Versions change frequently (think TensorFlow, PyTorch, etc.).
Without a reproducible setup, research cannot be trusted or reused.
🏛️ The Four Pillars of Reproducible Research
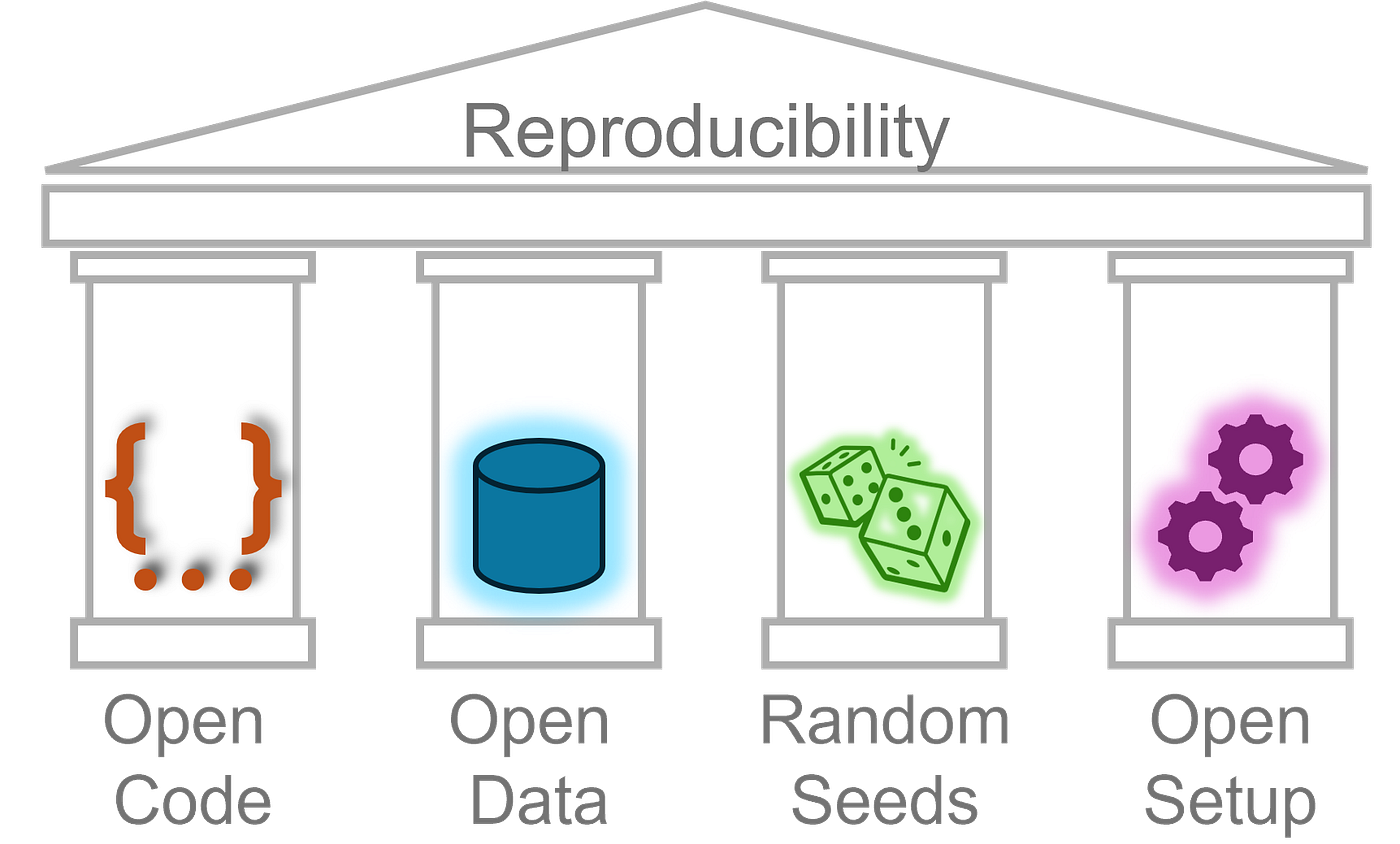
version control system, open and publicly available data, the usage of initialization seeds
for random functions, and a reproducible installation setup. GPU-Jupyter addresses
the fourth pillar, open setup.
Reproducibility isn’t just about sharing code and data — it’s about ensuring others can run your exact setup. The four pillars are:
- Open Code — Version-controlled, readable, and executable.
- Open Data — Publicly accessible, referable datasets.
- Random Seeds — For controlled randomness.
- Open Setup — The full environment, from OS to GPU drivers, should be reproducible.
While many efforts cover the first three, the Open Setup is often overlooked — and this is where GPU-Jupyter shines.
🚀 Meet GPU-Jupyter: Reproducibility with One Command

GPU-Jupyter is an open-source framework that packages the entire DL environment — including CUDA drivers, JupyterLab, ML libraries, and system-level configurations — into Docker containers. These containers are:
- GPU-accelerated
- Fully isolated from your host system
- Customizable and taggable
- Launchable with a single command
One-command reproducibility becomes a reality:
docker run --gpus all -p 8888:8888 cschranz/gpu-jupyter:<tag>
Why Docker?
Docker ensures OS-level isolation. That means:
- You don’t pollute your local machine version dependencies.
- Conflicts between TensorFlow, PyTorch, or CUDA versions are avoided.
- You can freeze and share environments via tagged images.
🧰 Standard vs. Customized Images
GPU-Jupyter supports both:
✅ Standard Images
Use pre-built, maintained containers from DockerHub:
docker run --gpus all -p 8888:8888 cschranz/gpu-jupyter:v1.9_cuda-12.6_ubuntu-24.04🛠️ Customized Images
Need your own packages, scripts, or dataset downloads? You can build your own reproducible container:
git clone https://github.com/iot-salzburg/gpu-jupyter
bash generate-Dockerfile.sh --python-only
docker build -t my-custom-gpu-jupyter .build/To share, push to DockerHub or your own registry.
Example:
docker run --gpus all -p 8888:8888 my-user/my-custom-gpu-jupyter:v1.0
Full example repo: github.com/iot-salzburg/reproducible-research-with-gpu-jupyter
🔄 Use Cases
1. Publish Reproducible Research
Cite the Docker image used in your paper:
All experiments were run using the image `cschranz/gpu-jupyter:v1.9_cuda-12.6_ubuntu-24.04`2. Reproduce a GPU-Jupyter-based Project
docker run --gpus all -p 8888:8888 cschranz/gpu-jupyter:<tag>3. Reproduce a Custom Image
If the author published their own Docker image:
docker run --gpus all -p 8888:8888 their-user/custom-image:tag4. Make Any Old Project Reproducible
Use a base GPU-Jupyter image, install original dependencies, and you’re done — no more dependency hell.
🧑💻 Example in Action

Here’s a sample session in Visual Studio Code, connected to a GPU-Jupyter container running remotely. The environment is isolated, version-controlled, and replicable by anyone with the image.
📚 Citing GPU-Jupyter (Paper under Review)
The scientific foundation of GPU-Jupyter is discussed in the preprint:
Schranz, C., Pilosov, M., Beeking, M. (2024). GPU-Jupyter: A Framework for Reproducible Deep Learning Research.
GitHub | Paper PDF
It emphasizes:
- The reproducibility crisis in ML
- The need for full-stack setups
- The role of Docker containers for experiment isolation
💡 Final Thoughts
Reproducible research isn’t optional — it’s a necessity. Especially in ML/DL, where GPU acceleration, fast-changing libraries, and complex workflows dominate.
With GPU-Jupyter, you get:
- 🧠 Reproducibility from code to CUDA
- 🧰 Docker-based OS isolation
- 📦 Shareable, taggable container images
- 🧪 Reproduction with one command
Try it, cite it, and make reproducibility your default.
Start here 👉 https://github.com/iot-salzburg/gpu-jupyter
The whole GPU-Jupyter Series:
- Set up Your own GPU-based Jupyter easily using Docker.
- Learn how to connect VS Code to your remote GPU-Jupyter instance to incorporate the advantages of an IDE and the GPU-Jupyter.
- 🧪 Reproducible Deep Learning Experiments with One Command: GPU-Jupyter
Enjoy running your own code on the GPU :)
